- Published on
Splitting production databases with minimal downtime
- Authors

- Name
- Mark Story
- https://mastodon.social/@markstory
At Sentry, our relational datastore is Postgres. We’re a write heavy application and we’ve had to scale Postgres both vertically and horizontally as Sentry has grown. In this post we’ll be covering how we operate Postgres to get higher write throughput.
How we operate postgres
We operate Postgres in fairly typical replication topologies. Applications connect to Postgres via a pgbouncer sidecar and each Postgres primary has multiple replicas for additional read capacity and to enable failover and maintenance operations.

There are many ways to scale Postgres horizontally. You can divide workloads by customer, or by product area or both. Thus far we’ve leveraged product area sharding in our Postgres clusters. We’ve used this process several times to create isolated shards of data so that we can continue to scale.
Splitting by product area instead of customer has allowed us to segment our infrastructure along product lines and isolate failure domains. If our billing system overwhelms Postgres, that can’t impact other products as they run on separate infrastructure.
Our largest region (the US region) is currently operating with 14 Postgres primaries. During our work to add the EU region, we needed to do another Postgres primary partition along the silo boundaries that we would have in our multi-region deployment.
Django with multiple databases
Sentry is built with Django and we use Django’s ORM extensively within our application. One of the great features that Django provides are database routers. Using a database router allows your application to remain mostly unaware of which connections database models are located on. One change you do have to make to your application is to use router for operations like transaction.atomic
from django.db import router, transaction
from sentry.models.user import User
with transaction.atomic(using=router.db_for_write(User)):
user = User.objects.get(id=request.user.id)
user.name = "mark"
user.save()
We have used Django routers for many years to handle our multiple Postgres cluster configuration. For our multi-region offering, we needed to expand the usage of Django routing to cover more control silo operations.
For the control silo split our Django router needed to evolve and become more powerful. While the exact implementation of our router is part of the saas only code base, the basic silo based router can be found here.
At a high-level the decision tree for our router is:
- Use the model’s
silo_limitannotation data to select the ‘default’ database for the current silo mode. - If the model can be routed in the current region, check if the model’s table has an explicit mapping to a logical connection. Logical connections are defined for the maximally partitioned region - the US region.
- Finally, resolve the logical connection to the physical one for the region. Each of our regions and tenants are scaled differently. In small regions multiple logical databases map to a single physical database cluster.
Preparing for a database split
When it comes time for us to split a new database primary out, we first have to perform some analysis on which models need to retain strong transactional boundaries, and where we can relax our consistency guarantees a bit.
For example, our control silo split would see us move User into control silo. There were many foreign keys between User and other tables like AlertRule.owner_id. While the relationship is still necessary, Users and AlertRules are never modified together within a transaction. In scenarios like this we can remove the foreign key constraint. In contrast the foreign key between User and UserEmail was retained as these models frequently change together and will both end up in control silo together. Our goal was to only remove foreign keys that would impede the silo separation, and nothing more.
With the transaction boundaries around control silo models well defined, we started removing foreign keys. In Django this takes the form of a series of migrations that remove constraints:
migrations.AlterField(
model_name="alertrule",
name="user",
field=sentry.db.models.fields.foreignkey.FlexibleForeignKey(
db_constraint=False,
on_delete=django.db.models.deletion.CASCADE,
to="sentry.user",
),
),
You may have noticed that our constraint was previously using cascading deletes. Because our tables would no longer benefit from cascading deletes at the database level, we developed a tombstone based subsystem that performs cascading deletes in an eventually consistent manner.
For the control silo split more than 80 such foreign keys needed to be removed. The reason there were so many was that our User model was moving to the control silo, and as you would expect many tables had references to Users.
With our foreign keys separated, we add a new database mapping in pgbouncer (e.g. control) and a connection configuration in django. Initially, the new control connection points to the Postgres primary that the table is in before the split. We then update Django’s database router to route the tables that are moving to the new control connection.
After these changes are made, the application treats the two connections as distinct connections and no transactions can be performed across the connections. Once the application is stable in this state, we begin the physical separation.
Physical Separation and Cutover
With our logical separation complete, our application and database state looks like:
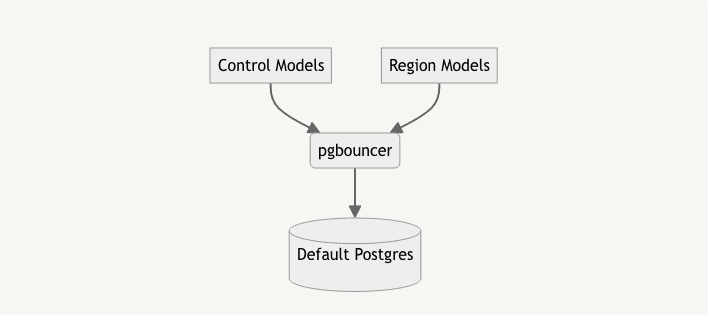
The next step is to create a new primary Postgres server with a replica set, and attach that to the existing Postgres as a replica.
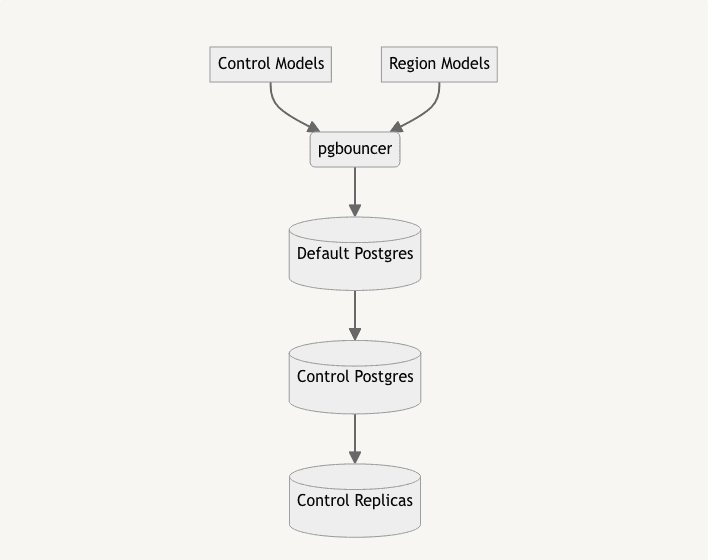
In order to split a Postgres primary, we have to take a short maintenance window. During the maintenance window we do a few operations:
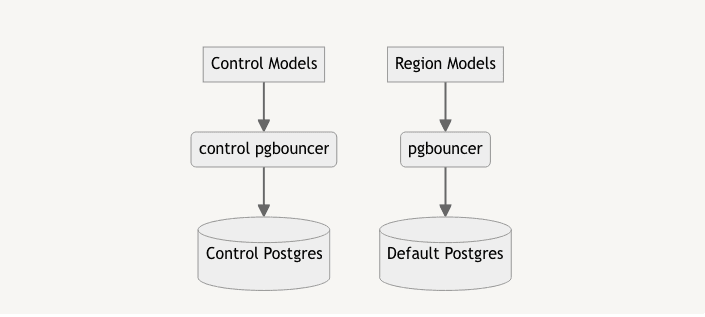
- Detach the new primary from replication and promote it to a primary.
- Update
pgbouncerconfiguration to point thecontroldatabase at the new primary by updating the hostname for the database mapping.
Because each application pod includes a pgbouncer our final result looks like:
In closing
Horizontally sharding out an application’s relation storage on domain boundaries has let us scale this far, and continues to be a promising solution to solve write capacity issues we face in Postgres. In the future we may need to explore customer level sharding when we are unable to relax transactional boundaries any further.